J’ai fait plusieurs ajustements sur mon cluster kubernetes (k3s) pour améliorer les performances de ce que j’héberge, sachant que tout ça tourne sur de petites machines peu performantes.
Stockage persistant sur SSD
J’avais initialement un disque dur mécanique pour le stockage (sur un serveur NFS), ce qui ralentissait significativement en cas d’accès concurrents. Le remplacer par un SSD a bien amélioré les performances.
Isolation des « noisy neighbors »
J’ai remarqué que les pods qui tournaient sur la même machine qu’un pod particulier étaient plus lent qu’ailleurs.
Ce pod est effectivement un « noisy neighbor »: toute les 5 minutes, il lance un traitement qui consomme beaucoup de ressources CPU, ce qui ralentissait les voisins.
Pour éviter ça, j’ai fait 2 choses:
- ajouter une « resource limit » de CPU à ce pod
- lui ajouter un label particulier, et configurer des podAntiAffinity sur les autres pods dont je voudrais préserver les performances
Réduction de la fréquence des probes
Les probes de k8s sont précieuses, mais consommatrices de ressources. Ca se sent bien plus sur mes petites machines que sur de gros serveurs, bien sûr.
Je ne parle pas des startupProbes, qui ne sont utilisées qu’au démarrage du pod, mais des livenessProbes et readinessProbes.
Par défaut, ces 2 probes sont exécutées toute les 10 secondes, cf https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#configure-probes.
Augmenter periodSeconds permet de limiter l’overhead de ces probes. Au prix d’un délai de réactivité plus long en cas de problème sur un pod (sauf à réduire aussi failureThreshold)
D’autre part, dans mon cas de figure, les readinessProbes ont peu d’utilité tant que je ne déploie qu’un seul pod par deployment (et que j’y contrôle la même URL que la livenessProbe). Je les ai donc supprimés, pour ne garder que les livenessProbes.
Utilisation d’un Ingress plutôt qu’un loadbalancer externe pointant sur les NodePorts
Au départ, j’avais configuré le reverse-proxy frontal (Apache) de mon auto-hébergement en load-balancer sur mes différents nodes (en accédant aux NodePorts). Mais j’ai remarqué plusieurs soucis si je mettais une NetworkPolicy: même en acceptant l’accès depuis l’IP de mon load-balancer, seul le node où tournait le node était accessible. Ce qui avait plusieurs conséquences:
- j’étais obligé de lister tous mes nodes dans le load-balancer (et de tenir cette liste à jour si j’ajoutais un node)
- j’avais plein d’erreurs dans les logs du load-balancer frontal (à chaque fois qu’il essayait de contacter un node où le port était fermé)
- les performances étaient moins stables, avec des lenteurs récurrentes (là aussi, quand il essayait un mauvais node, je suppose)
Pour éviter ces problèmes, j’ai simplement utilisé un Ingress au lieu des NodePorts. Résultat: un temps de réponse bien plus stable:
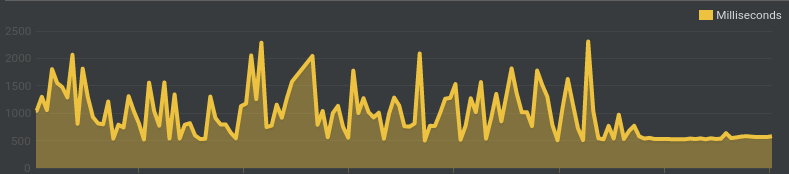
Dans un premier temps, je garde mon reverse-proxy frontal, et je lui laisse gérer le SSL Let’s Encrypt. Il ne fait plus de load-balancing, et envoie sur l’Ingress le traffic correspondant. A terme, quand tout sera basculé sur k8s, j’enverrai probablement le traffic directement sur l’Ingress (et le laisserai gérer les certificats SSL)
Je n’ai pas noté de différence notable de performance en accédant (depuis le reverse-proxy frontal) à l’Ingress en http ou https. On voit ci-dessous, à partir de 17h environ que je suis passé en https: je perds apparemment autour de 40 millisecondes (en passant de 530 à 570 millisecondes environ):
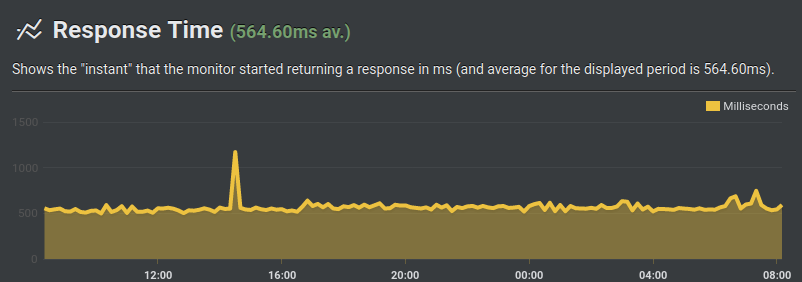
Il faut néanmoins configurer ce reverse-proxy frontal pour qu’il ignore les erreurs de TLS (puisqu’il s’agit pour l’instant d’un certificat auto-signé):
ProxyPass / https://k3s-ingress/
ProxyPassReverse / https://k3s-ingress/
ProxyPreserveHost on
# Pour accepter le certificat auto-signé de l'ingress, si appelé en https
SSLProxyEngine on
SSLProxyVerify none
SSLProxyCheckPeerCN off
Logging du traffic de l’Ingress Traefik
Pour configurer Traefik sur k3s, je déploie un manifest de type HelmChartConfig. J’y active le logging, mais aussi le nécessaire pour que l’IP d’origine soit écrite dans les logs (et non l’IP du reverse-proxy frontal, qui est le 192.168.x.y ci-dessous). Et enfin le nécessaire pour que l’heure loggée soit dans ma timezone (et non en UTC):
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: traefik
namespace: kube-system
spec:
valuesContent: |-
# Enable access logs in stdout
logs:
access:
enabled: true
# To have the original IP in X-Forwarded-For headers (end prefer local Traefik pod if available)
service:
spec:
externalTrafficPolicy: Local
# To have logs in the right timezone
env:
- name: TZ
value: Europe/Paris
additionalArguments:
# To preserve existing X-Forwarded-For headers from frontal reverse-proxy
- "--entryPoints.web.forwardedHeaders.trustedIPs=192.168.x.y/32"
- "--entryPoints.websecure.forwardedHeaders.trustedIPs=192.168.x.y/32"
- "--entryPoints.web.proxyProtocol.trustedIPs=192.168.x.y/32"
- "--entryPoints.websecure.proxyProtocol.trustedIPs=192.168.x.y/32"
# To have logs in the right timezone
- "--accesslog.fields.names.StartUTC=drop"
Redondance de l’Ingress
Par défaut, k3s déploie un seul pod d’Ingress, mais fait en sorte que tous les nodes écoutent sur les ports 80 et 443, en redirigeant le flux réseau vers le (ou les) pods d’Ingress (via Klipper).
J’ai choisi de mettre une nodeAffinity pour que ce pod d’Ingress soit de préférence sur le control-plane, parce qu’il est stable et peu chargé dans mon contexte.
Pour autant, je voulais prendre en compte la possibilité d’une indisponibilité du control-plane. Et, si le control-plane est éteint, il ne va pas détecter l’indispo de l’Ingress, et ne va donc pas le relancer sur un autre node (je n’ai déployé qu’un seul control-plane, sans haute dispo). Il faut donc au moins 2 pods d’Ingress.
Ensuite, une possibilité aurait été de configurer le reverse-proxy frontal en load-balancing sur différents nodes. Cela fonctionnerait, mais ajouterait du traffic réseau inutile (passage par une machine intermédiaire). D’autre part, cela serait plus sensible à la charge des différents nodes (dont certains sont très peu puissants ou très chargés). Et surtout, je risquerais de retomber sur les ralentissements en cas de node indisponible.
J’ai choisi une autre solution, qui privilégie les performances: mon reverse-proxy frontal renvoie vers un alias DNS (« k3s-ingress », dans mon exemple), qui pointe habituellement vers le control-plane. Le fait d’utiliser l’option externalTrafficPolicy: Local assure que le traffic sera redirigé vers le pod d’Ingress local plutôt que distant. Cf https://kubernetes.io/docs/tasks/access-application-cluster/create-external-load-balancer/#preserving-the-client-source-ip
En cas d’indispo du control-plane, il faut « simplement » que je change cet alias DNS pour l’IP d’un autre noeud du cluster k3s: le flux est redirigé vers le second pod d’Ingress (où qu’il soit). Je m’assure que le second pod n’est pas sur le control-plane avec une podAntiAffinity.
C’est un choix lié à mon contexte: je préfère être un peu plus performant, quitte à avoir besoin d’une intervention manuelle sur ce (rare) cas d’indispo.
Au final, cela revient à ajouter ce qui suit dans le HelmChartConfig:
# Deploy 2 instances
deployment:
replicas: 2
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
# Prefer to run the primary instance on control-plane
- weight: 1
preference:
matchExpressions:
- key: node-role.kubernetes.io/control-plane
operator: In
values:
- "true"
# Both instances must not run on the same node
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app.kubernetes.io/name: '{{ template "traefik.name" . }}'
app.kubernetes.io/instance: '{{ .Release.Name }}-{{ .Release.Namespace }}'
topologyKey: kubernetes.io/hostname
NB: le jour où je laisserai l’Ingress gérer les certificats LetsEncrypt, il faudra que j’utilise cert-manager, et non la fonctionnalité intégrée dans Traefik, qui n’est pas compatible avec plusieurs pods.