J’ai mis en place un PRA pour mon auto-hébergement k3s, basé sur les snapshots btrfs.
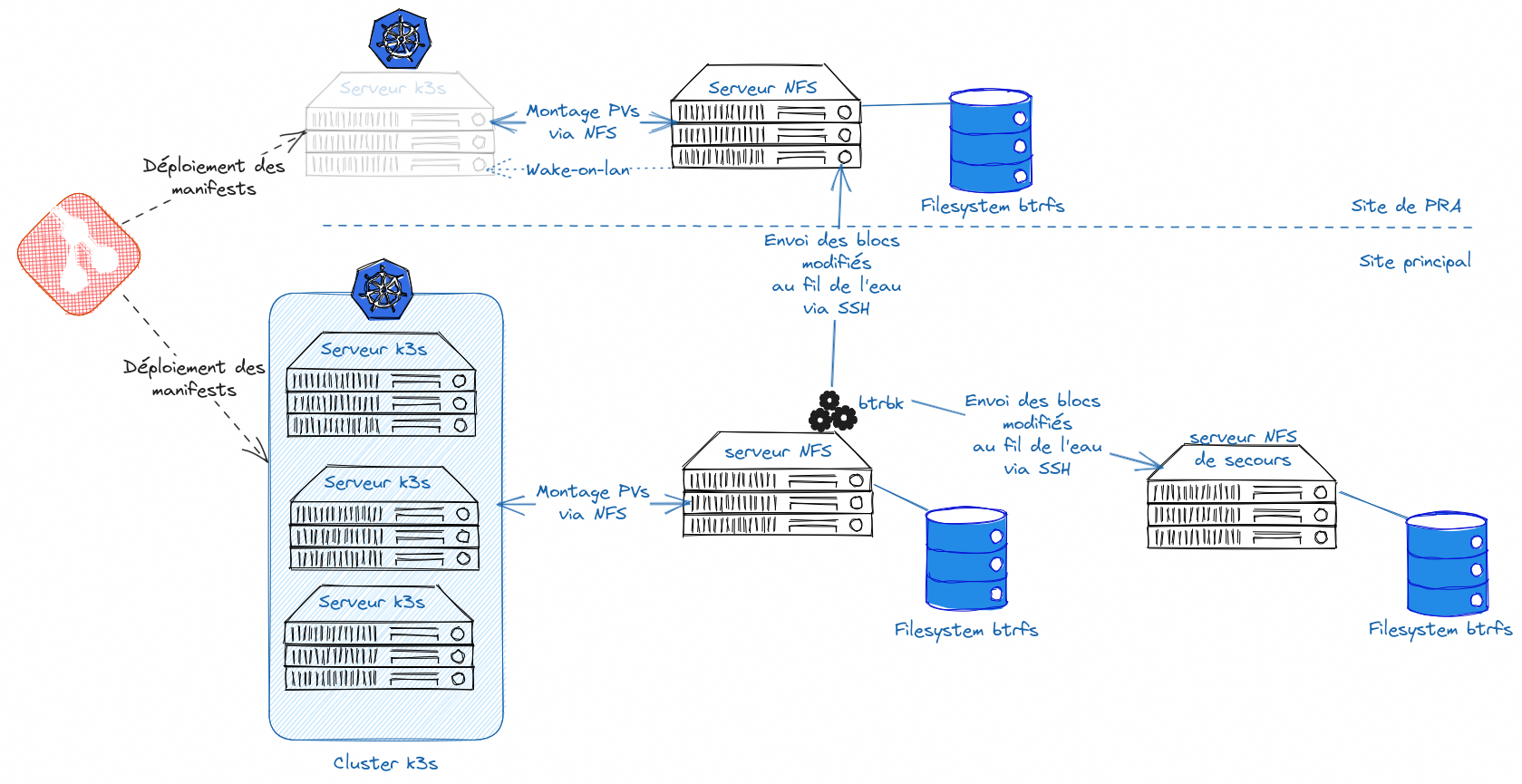
Synchro des données
Comme je l’ai expliqué dans un article précédent, je synchronise les données de mon NAS (serveur NFS principal) vers 2 autres serveurs: un serveur de secours (sur mon site principal), et un autre serveur sur mon site de PRA. C’est une synchronisation « au fil de l’eau », avec différentes storageClasses en fonction de la fréquence de synchronisation nécessaire.
Tout ça s’appuie sur la notion de snapshots btrfs, et sa capacité à envoyer les snapshots (avec les blocs modifiés du filesystem) vers un autre filesystem btrfs distant (via SSH).
Les snapshots locaux du serveur NFS principal sont déjà une première sécurité, et permettent de revenir en arrière en cas d’effacement accidentel, par exemple.
Si indispo du serveur NFS principal
Je peux basculer mon cluster kube sur le serveur NFS de secours. Sur le principe, il suffit de faire pointer les PVs vers un autre serveur NFS.
Oui, sauf que kube refuse que je modifie une storageClass en direct. Donc j’ai d’autres storageClasses toutes prêtes, identiques aux principales, mais qui pointent vers le NFS de secours.
Oui, mais là aussi, kube m’empêche de modifier la storageClass d’un PVC en direct.
Cela m’oblige donc à supprimer tous les manifests (au moins ceux qui utilisent des PVCs) puis les recréer (kubectl delete -f / kubectl apply -f et/ou helm delete/helm install).
Pour que ça fonctionne, il est nécessaire que le provisioner ait une manière déterministe de nommer les sous-répertoires qui correspondent à chacun des PVs. De sorte que ce soit le même nom de répertoire recherché par les nouveaux PVCs (qui n’auront pas le même id, notamment). C’est heureusement possible avec https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner, en spécifiant un pathPattern adapté: j’utilise ${.PVC.namespace}/${.PVC.name}
Si indispo du site complet
Dans ce cas, il faut partir en PRA.
Sur le site de PRA, mon cluster k3s est constitué d’une seule machine, éteinte par défaut. Quand j’en ai besoin, je l’allume via une commande wake-on-lan depuis l’autre serveur.
Le serveur qui reçoit les snapshots btrfs fait aussi serveur NFS, utilisé par le serveur k3s (avec des storageClasses adaptées).
Il faut que je déploie tous mes manifests (depuis git) sur le serveur k3s, en changeant simplement de storageClass.
Et il faut ensuite que je bascule les résolutions DNS vers les IP du site de PRA.
NB: dans l’état actuel de mon infra, j’ai aussi un reverse-proxy frontal devant l’ingress k3s. Et c’est ce reverse-proxy frontal qui gère les certificats SSL letsencrypt (avec certbot). J’ai donc besoin de synchroniser (une fois par jour) la configuration de ce reverse-proxy, et les certificats letsencrypt. A terme, j’espère pouvoir l’enlever, et que le SSL soit géré par l’ingress k3s (qui serait directement exposé sur Internet)
Retour en mode nominal
Quand le site principal refonctionne, ses (anciennes) données vont se synchroniser à nouveau vers le site de PRA. Aïe, est-ce que cela va écraser mes données du PRA? Non, les données sont envoyées à chaque fois sur des nouveaux snapshots. Donc le snapshot utilisé par le serveur NFS de PRA ne sera pas affecté (il a été créé manuellement: voir mon article précédent).
Pour revenir en mode nominal, il faudra bien sûr remettre à jour les données sur le serveur NFS principal (le faire via rsync me parait le plus adapté), puis rebasculer les DNS. Avec une nouvelle interruption de service.
Et l’intégrité des données?
Un snapshot du filesystem est toujours consistant d’un point de vue filesystem, c’est-à-dire qu’il prend une photo du même état de tous les fichiers à un instant t. Pas de décalage entre l’état des différents fichiers du snapshot. C’est déjà une excellente chose, et ça suffit dans un grand nombre de cas.
Mais certains pods sont des bases de données (PostgreSQL, MariaDB, redis etc). Et les snapshots du filesystem sont faits « à chaud », c’est-à-dire sans arrêter les moteurs de BDD.
Est-ce risqué? Sur le principe, oui. Il vaudrait mieux passer par un export/import de dump (qui est forcément intègre) ou d’autres solutions « transaction-consistent ». C’est aussi risqué que si un serveur de BDD était arrêté violemment (en le débranchant électriquement sans prévenir), mais les moteurs de BDD sont souvent conçus pour se sortir automatiquement de ce type de situation.
C’est une sauvegarde dite « crash-consistent », ou « point-in-time-consistent ».
A noter que, comme toutes mes données sont sur ce même filesystem, cela m’assure de n’avoir aucun décalage entre les différents services hébergés.
RPO/RTO
Quels sont mes RPO et RTO avec ce PRA?
Le RPO dépend de la storageClass que j’ai utilisée: entre 1h, 1 jour et 1 semaine.
J’ai eu l’occasion de devoir basculer sur mon serveur NFS de secours. Mon RTO était d’environ 2h entre le temps de détecter l’incident, l’analyser, choisir la solution et le résoudre complètement (alors que je travaillais ce jour-là).
Je n’ai pas encore eu l’occasion de faire un « vrai » PRA en conditions réelles, mais ai testé de basculer un service individuellement: le RTO est du même ordre de grandeur, un peu plus important puisqu’il y a quelques étapes en plus (DNS, notamment, dont le temps de propagation peut jouer: choisir un TTL en fonction)
Évidemment, ces RTOs ne sont valables qu’en journée, et si je suis un peu disponible. Si je dors ou suis AFK, ça peut être bien plus long.
Bilan
Je suis très content de ce système, qui me parait bien adapté dans mon contexte.
Il a l’avantage d’être simple à mettre en œuvre, très peu couteux en ressources, et de gérer avec un même outillage les sauvegardes et le PRA.
Étant donné la faible montée en charge de mes services, et surtout le fait qu’il n’y ait quasiment aucune activité la nuit, le risque sur l’intégrité des données m’a paru très faible. Au pire, j’aurai toujours un snapshot intègre pris pendant la nuit.
J’ai oublié de préciser que j’ai fait le choix que le failover ou le PRA se fasse en mode légèrement dégradé: le serveur NFS de failover est plus lent (disque HDD au lieu de SSD), et mon unique serveur k3s de PRA ne peut faire tourner que les services les plus importants (les secondaires restant inaccessibles).
Pour mes besoins, le RPO est tout à fait satisfaisant, et le RTO dépend surtout de ma disponibilité.
Mise à jour le 06/10/2023: même si je suis satisfait de l’utilisation de NFS comme stockage persistant dans mon contexte, ce n’est pas quelque chose que je peux conseiller dans le cas général, notamment pour de la production en entreprise. En cas d’arrêt brutal d’un node, de micro-coupures réseau, ou de problème sur le serveur NFS, les données peuvent être corrompues. Cela m’est déjà arrivé plusieurs fois avec les données de bases PostgreSQL. Evidemment, les snapshots btrfs permettent très facilement de restaurer une sauvegarde récente, mais ce n’est pas idéal… D’autre part, certains applicatifs précisent qu’ils ne supportent pas que leurs données soient sur NFS: c’est le cas de Prometheus par exemple (cf https://prometheus.io/docs/prometheus/latest/storage/)